
5. Cox–Ingersoll–Ross process#
The purpose of this notebook is to provide an illustration of the Cox-Ingersoll-Ross Processs and some of its main properties.
Before diving into the theory, let’s start by loading the libraries
matplotlib
together with the style sheet Quant-Pastel Light.
These tools will help us to make insightful visualisations.
5.1. Definition#
The Cox-Ingersoll-Ross (CIR) model describes the dynamics of interest rates via a stochastic process which can be defined by the following Stochastic Differential Equation (SDE)
with initial condition \(X_0 =x_0\in\mathbb{R}\), and where \(W_t\) is a standard Brownian motion, and the three parameters are constants:
\(\theta>0\) : speed or mean reversion coefficient
\(\mu \in \mathbb{R}\) : long term mean
\(\sigma>0\) : volatility.
5.1.1. Existence and Uniqueness#
In order to demonstrate that equation (5.1) has a solution we need to introduce the following two results which can be found in [Jeanblanc, Yor, Chesney, 2009].
Theorem 1. Consider the SDE
Suppose \(\varphi : (0,\infty) \rightarrow (0,\infty)\) is a Borel function such that
If any of the following conditions holds, then the equation admits a unique solution which is is strong. Moreover the solution \(X\) is a Markov process.
the function \(b\) is bounded, the function \(\sigma\) does not depend on the time variable and satisfies
and \(|\sigma|\geq \epsilon >0\).
\(b\) is Lipschitz continuous, and
\(b\) is bounded, and \(\sigma\) does not depend on the time variable and satisfies
where \(f\) is a bounded increasing function, \(|\sigma|\geq \epsilon >0\).
Theorem 2. (Comparison Theorem) Consider the two SDEs
where the functions \(b_i\) are both bounded and at least one of them is Lipschitz; and \(\sigma\) satisfies condition (2) or (3) in Theorem 1. Suppose also that \(X^1_0 \geq X^2_0,\) and \(b_1(x) \geq b_2(x)\). Then \(X^1_t \geq X^2_t\) for all \(t\), almost surely.
Now, in order to prove that (5.1) has a solution, let us consider the following SDE
with the same initial condition and constant parameters as in (5.1). Note that in (5.2) we take absolute value before applying the square root which guarantees that this is well-defined.
Taking \(\varphi (x) = cx\), we have
which means that condition (1) in Theorem 1 holds. Thus equation (5.2) admits a strong solution – which is indeed a Markov process.
Observe that for \(\mu=0\) and \(x_0=0\), the solution of (5.2) is \(X_t =0, \forall t\geq0\). Then, the Comparison Theorem tells us that assuming \(\theta\mu >0\),implies that
In such case, we can ommit the absolute value in the diffusion coefficient and simply consider the positive solution of (5.4) whenever \(\theta \mu >0\) and \(x_0>0\). This demonstrates that (5.2) admits a unique solution which is is strong, and is a Markov process.
5.1.2. CIR process is a Bessel process#
Proposition 1. The CIR process (5.1) is a Bessel Squared process transformed by the following space-time changes:
where \(Y =\{Y_s, s\geq 0\}\) is a Besses Squared process \(BESQ^{\alpha}\), with dimension \(\alpha = \dfrac{4\theta \mu}{\sigma^2}\).
Proposition 1 implies that we have the following cases:
If \(2\theta\mu \geq \sigma^2\), a CIR process starting from a positive initial condition \(x_0\), stays strictly positive
If \(0 \leq 2\theta\mu < \sigma^2\), a CIR process starting from a positive initial condition \(x_0\), hits zero with probablilty \(p\in(0,1)\) in the case \(\theta<0\); and almost surely in the case \(\theta\geq 0\).
If \(2\theta \mu <0\), a CIR process starting from a positive initial condition \(x_0\) reaches zero almost surely.
5.2. Expectation and Variance#
For each \(t>0\), the conditional marginal \(X_t|X_0\) from a CIR process satisfies
and
In order to verify this, let us introduce the function \(f(t,x) = x e^{\theta t}\). Note that this is exactly the same function that we used to find the solution of the SDE associated to the Vasicek process. Then, Ito’s formula implies
Thus
Note
📝 We have not solve the equation explicitely since \(X_s\) is still present in the integral with respect to the Brownian motion. However, this expression allows us to calculate the conditional expectation and variance of the marginal \(X_t\).
To calculate the expectation of \(X_t\) we simply use the linearity of the expectation and the fact that the Ito integral is a martingale. This allows us to obtain:
Note
📝 This expectation is equal to the one obtained for the Vasicek process marginals. Later we will see that the marginals follow different distributions.
For the variance, we have
where the last equality follows by taking all non-stochastic terms out of the expectation in the first term and using the isommetry property of the Ito integral in the second term. Next, we use the fact that the two Ito integrals w.r.t. Brownian motion are martingales to obtain
Note
📝 The second term in the last expression is equal to the variance of the marginal from a Vasicek process multiplied by \(\mu\).
5.2.1. Python Implementation#
For given \(x_0, \theta>0, \mu, \sigma>0\) and \(t>0\) we can implement the above formulas for the expectation, and variance, as follows.
import numpy as np
x0 = 2.0
theta = 1.0
mu = 3.0
sigma = 0.5
t= 1.0
exp = x0*np.exp(-1.0*theta*t) + mu*(1.0 - np.exp(-1.0*theta*t))
var = (sigma**2/theta)*x0*(np.exp(-1.0*theta*t)- np.exp(-2.0*theta*t)) + (mu*sigma**2/(2.0*theta))*(1 - np.exp(-1.0*theta*t))**2
print(f'For x_0={x0}' , f'theta={theta}',f'mu={mu}', f'sigma=.{sigma}', f't={t}', sep=", ")
print(f'E[X_t] = {exp: .6f}')
print(f'Var[X_t] = {var :.6f}')
For x_0=2.0, theta=1.0, mu=3.0, sigma=.0.5, t=1.0
E[X_t] = 2.632121
Var[X_t] = 0.266113
5.3. Marginal Distributions#
The marginal distribution \(X_t | x_0\) , simply denoted by \(X_t\), has probability density function
where where \(I_{\nu}\) is the modified Bessel function, and
and
Then the random variable \(Y_t = X_t \dfrac{e^{\theta t}}{c(t)}\) has density
where
and
That is, \(Y_t\) follows a non-central Chi-squared distribution
So, \(X_t\) follows a non-central Chi-square distribution (with \(\delta\) degrees of freedom, non-centrality parameter equal to \(\alpha\)) scaled by \(scale = c(t)e^{-\theta t}\). Note that we can write these quantities in terms of the SDE parameters initial condition as follows:
Note
The number of degrees of freedom \(\delta\) does not depend on the initial condition \(x_0\). Moreover, \(\delta\) does not depend on \(t\)! which means that the number of degrees of freedom remains constant as the process evolves.
The non-centrality parameter \(\alpha\) does not depend on the long-term mean \(\mu\).
The scale depends neither on the long-term mean \(\mu\) nor on the initial condition \(x_0\).
5.3.1. Marginal Distributions in Python#
We can implement the marginal distributions in Python by using equations (5.9) to (5.12) which tells us that \(X_t\) follows a scaled non-central chi-squared distribution. One way to do this is by using the object ncx2 from the library scipy.stats. The next cell shows how to create \(X_1\) using this method.
from scipy.stats import ncx2
import numpy as np
x0 = 2.0
theta = 1.0
mu = 3.0
sigma = 0.5
t =1.0
delta = 4.0 * theta * mu / sigma**2
alpha = (4.0 * theta * x0) / (sigma**2 * (np.exp(theta*t)-1.0))
scale = (sigma**2 / 4.0 * theta) * (1.0 - np.exp(-1.0*theta*t))
X_1 = ncx2(df=delta,nc=alpha,scale=scale)
# Now we can calculate the mean and the variance of X_1
print(X_1.mean())
print(X_1.var())
2.632120558828558
0.2661132293025628
Another way to do this is by creating an object CIR from aleatory.processes and calling the method get_marginal on it. The next cell shows how to create the marginal \(X_1\) using this method.
from aleatory.processes import CIRProcess
x0 = 2.0
theta = 1.0
mu = 3.0
sigma = 0.5
t =1.0
process = CIRProcess(theta=theta, mu=mu, sigma=sigma, initial=x0)
X_1 = process.get_marginal(t=1)
# Now we can calculate the mean and the variance of X_1
print(X_1.mean())
print(X_1.var())
2.632120558828558
0.2661132293025628
Hereafter, we will use the latter method to create marginal distributions from the CIR process.
5.3.2. Probability Density Functions#
The probability density function (pdf) of the marginal distribution \(X_t\) given \(x_0>0\), is given by equation (5.7)
Let’s take a look at the density function of \(X_1\) for different values of \(\theta\), \(\mu\), and \(\sigma\).
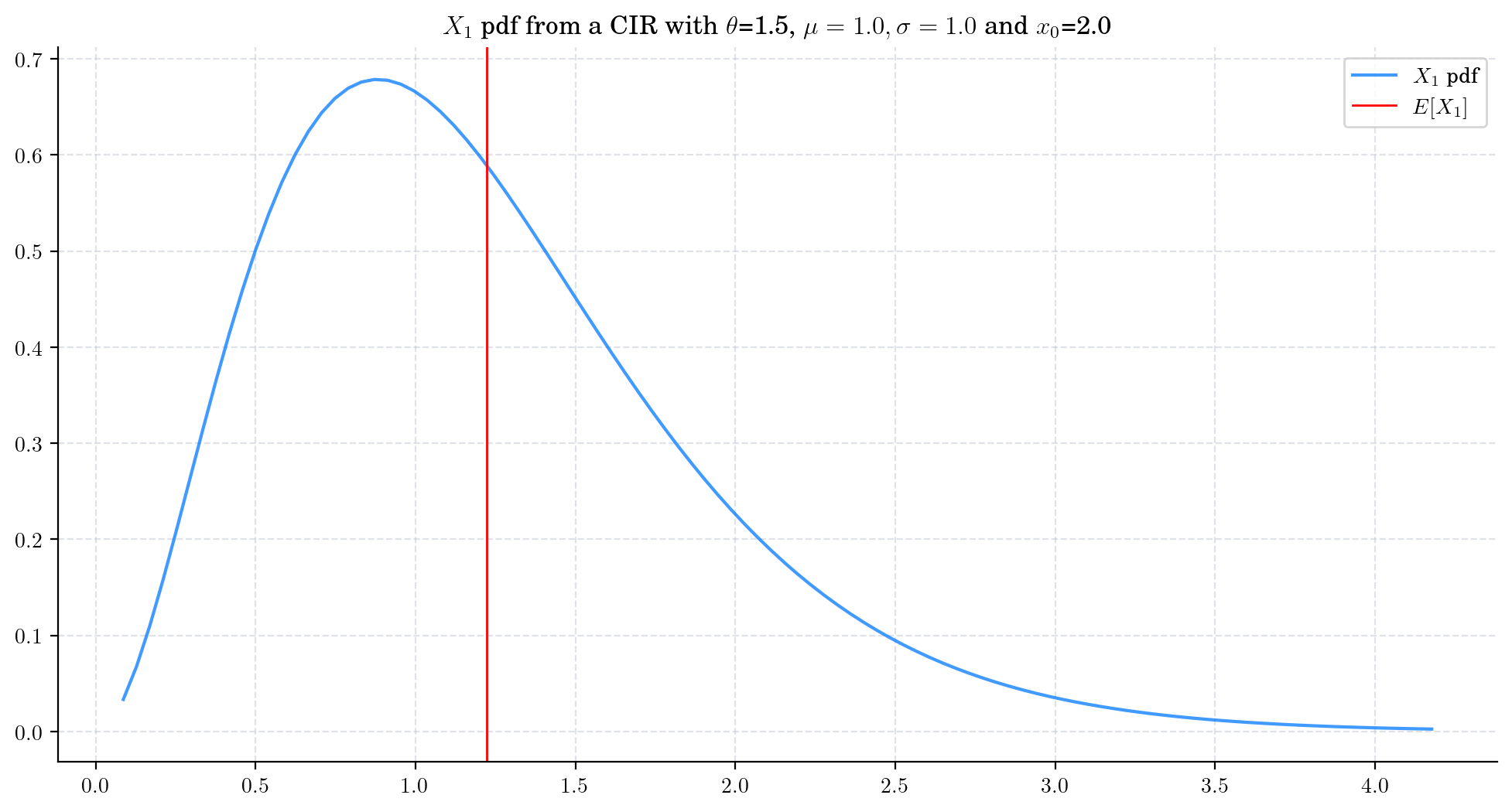
First we consider the process
CIRProcess(theta=1.5, mu=1.0, sigma=1.0, initial=2.0) and plot the marginal density of \(X_1\).
Note that the distribution is skewed and that its mean is still far from the long term mean \(\mu=1.0\).
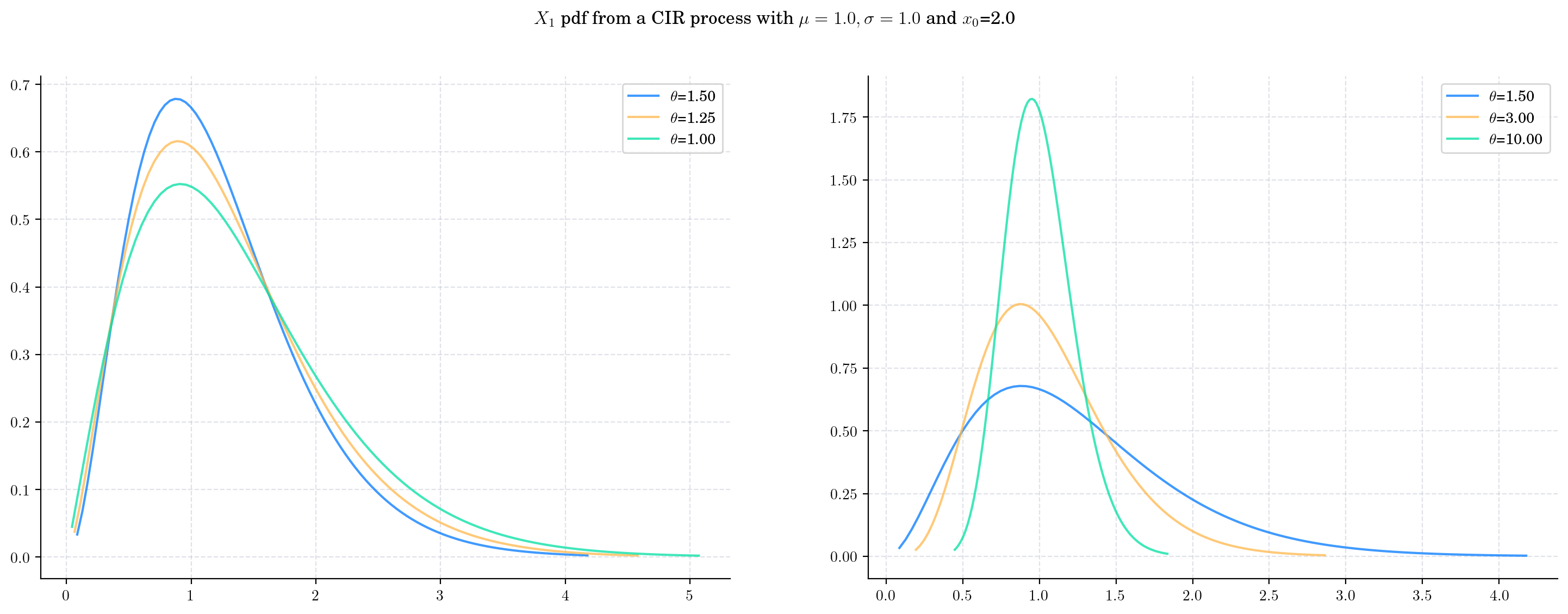
Next we vary the value of the parameter \(\theta\) (the speed of reversion) CIRProcess(theta, mu=1.0, sigma=1.0, initial=2.0) and plot the corresponding densities of \(X_1\).
Note that the change in the value of \(\theta\) impacts both the mean and the variance of the density.
As \(\theta\) increases:
The expectation goes from being close to the initial point \(x_0 = 2.0\) to being close to the long term mean \(\mu=1.0\).
The variance decreases and the distribution becomes more concentrated.
Both the degrees of freedom and the non-centrality parameters increase. We can see this by observing how the shape of the density changes becoming more symmetric.
The scale decreases.
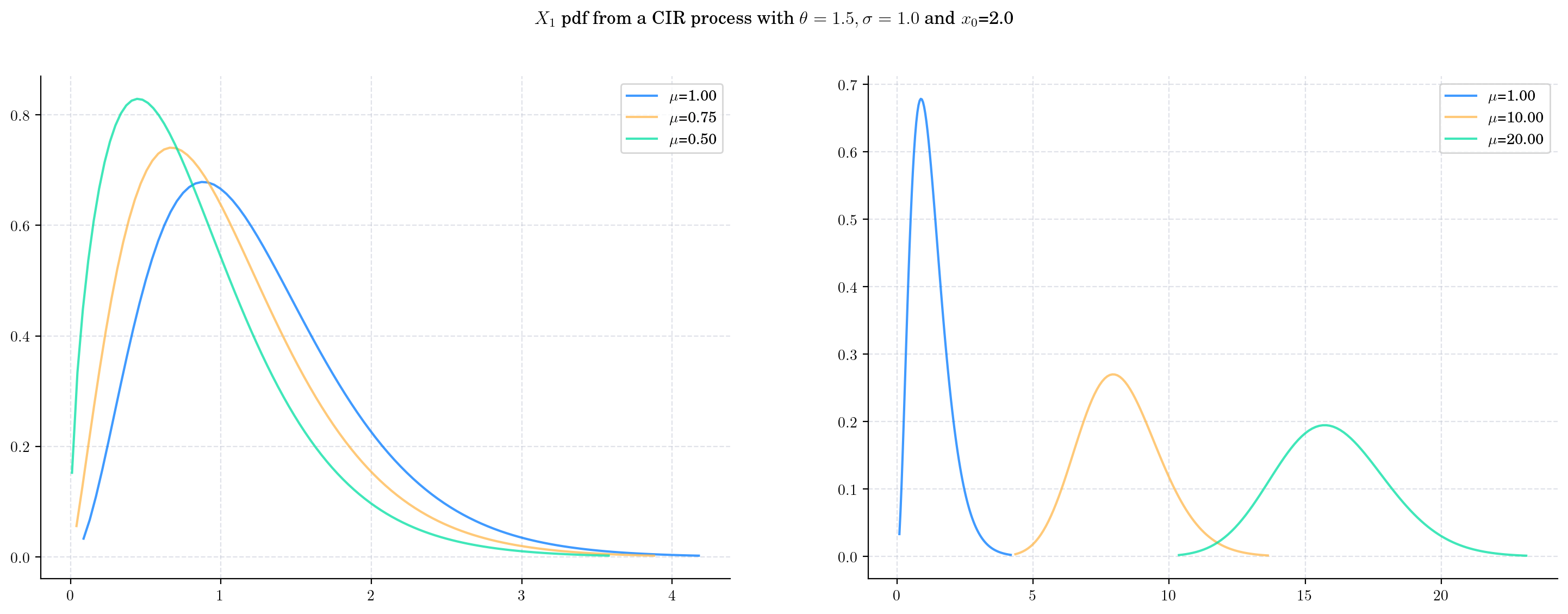
Next we vary the value of the parameter \(\mu\) (the long term mean) in a CIRProcess(theta=1.5, mu=mu, sigma=1.0, initial=2.0) and again plot the densities corresponding to \(X_1\).
As \(\mu\) increases:
The mean of the density follows the direction of the parameter \(\mu\) which is expected since it will converge to it when \(t\) goes to infinity.
The variance increases and the density becomes wider
The degrees of freedom increase, and the density becomes more symmetric
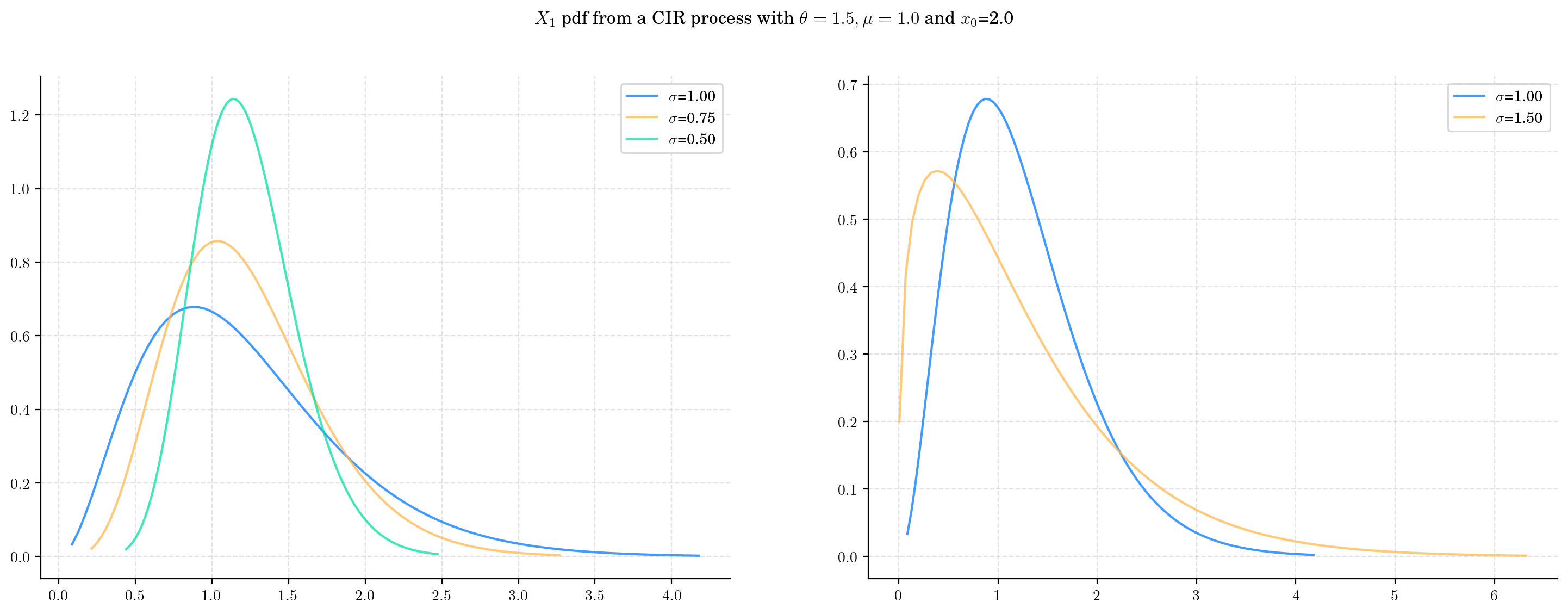
Next we vary the value of the parameter \(\sigma\) (the volatility) in CIRProcess(theta=1.5, mu=1.0, sigma=sigma, initial=2.0) and again plot the densities of \(X_1\).
As \(\sigma\) increases:
The mean remains constant
The variance of \(X_1\) increasesand the distribution becomes wider. We can see this by looking at the range in the x-axis of the plots.
The degrees of freedom decrease. The density becomes more asymmetric.
The non-centrality parameter decreases and the scale increases
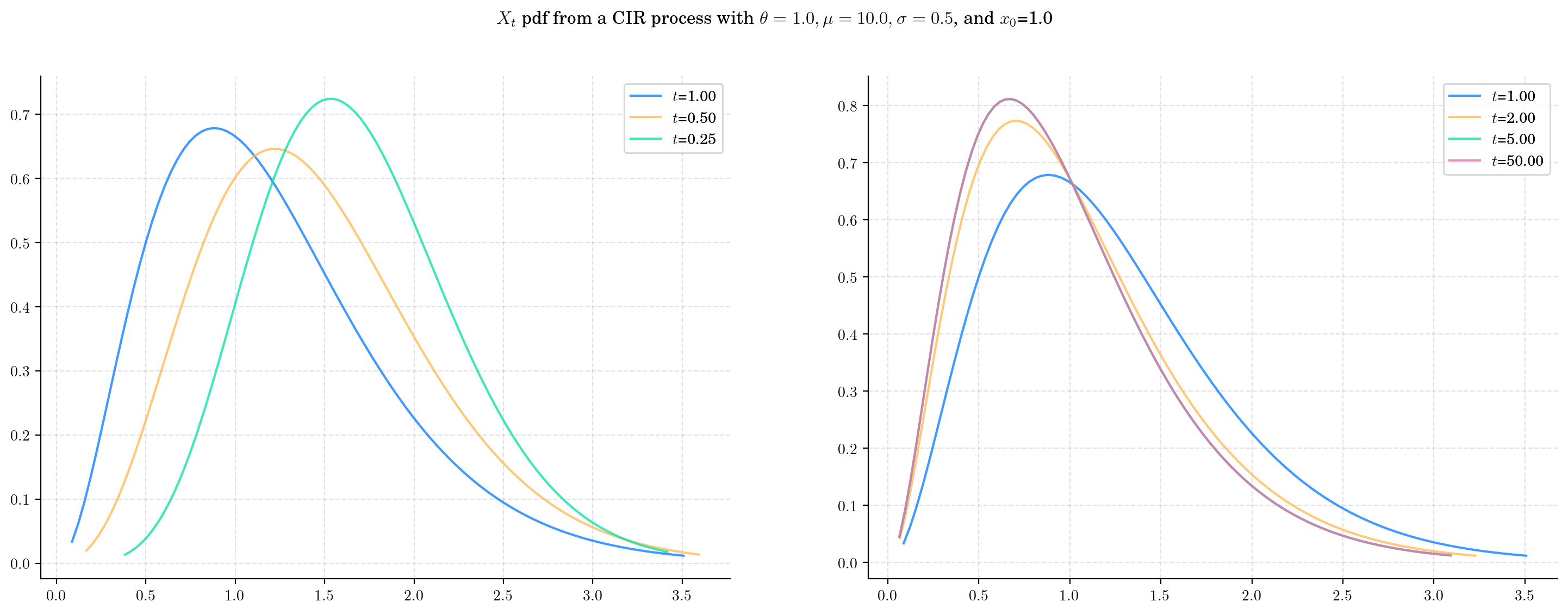
Finally, we will keep all parameters fixed as CIRProces(theta=1.5, mu=1.0, sigma=1.0, initial=2.0) and plot the densities of \(X_t\) for a range of \(t\) values.
As \(t\) increases:
The expectation goes from being close to the initial point \(x_0 = 2.0\) to being close to the long term mean \(\mu=1.0\).
The variance also increases but note that it stabilises as convergence happens.
The degrees of freedom remain constant
The non-centrality parameter tend to zero
The scale converges to a constant
5.3.3. Sampling#
Now, let’s see how to get a random sample from \(X_t\) for any \(t>0\).
The next cell shows how to get a sample of size 5 from \(X_1\).
# from aleatory.processes import CIRProcess
process = CIRProcess(theta=1.0, mu=10.0, sigma=0.5, initial=1.0)
X_1= process.get_marginal(t=1.0)
X_1.rvs(size=5)
array([7.04367385, 6.81165586, 7.28559614, 6.17234783, 7.8558725 ])
Similarly, we can get a sample from \(X_{10}\)
X_10 = process.get_marginal(t=10)
X_10.rvs(size=5)
array([11.68731396, 10.2250783 , 10.93274867, 12.82746048, 10.53331732])
5.4. Simulation#
In order to simulate paths from a stochastic process, we need to set a discrete partition over an interval for the simulation to take place.
For simplicity, we are going to consider an equidistant partition of size \(n\) over \([0,T]\), i.e.:
Then, the goal is to simulate a path of the form \(\{ X_{t_i} , i=0,\cdots, n-1\}\). We will use Euler-Maruyama approximation.
5.4.1. Simulating and Visualising Paths#
We can simulate several paths from a Vasicek process and visualise them we can use the method plot from the aleatory library.
Let’s simulate 10 paths over the interval \([0,1]\) using a partition of 100 points.
Tip
Remember that the number of points in the partition is defined by the parameter \(n\), while the number of paths is determined by \(N\).
# from aleatory.processes import CIRProcess
process = CIRProcess(theta=1.0, mu=10.0, sigma=0.5, initial=2.0)
fig = process.plot(n=100, N=10, title='10 paths of the CIR Process on [0,1]')
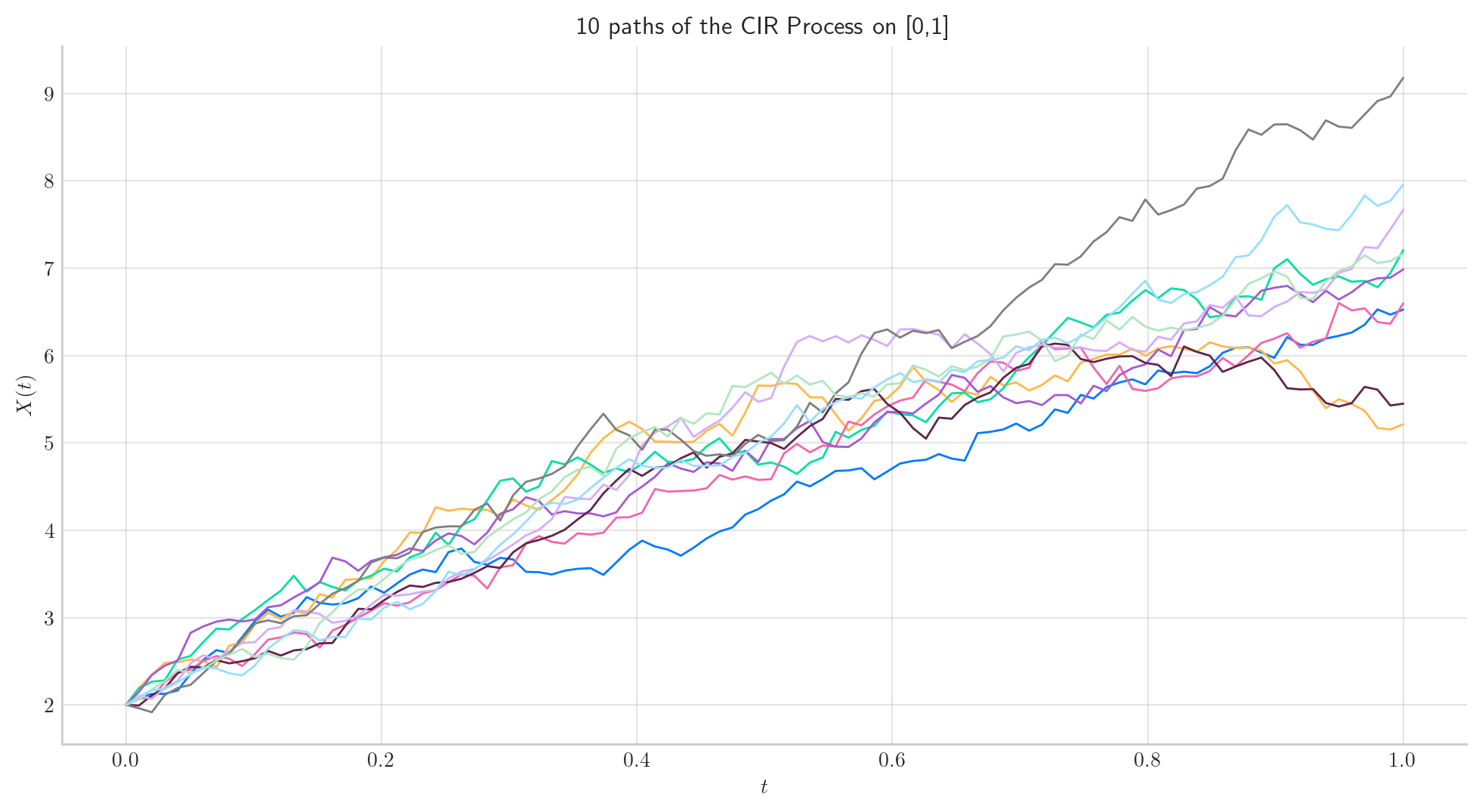
Note
In all plots we are using a linear interpolation to draw the lines between the simulated points.
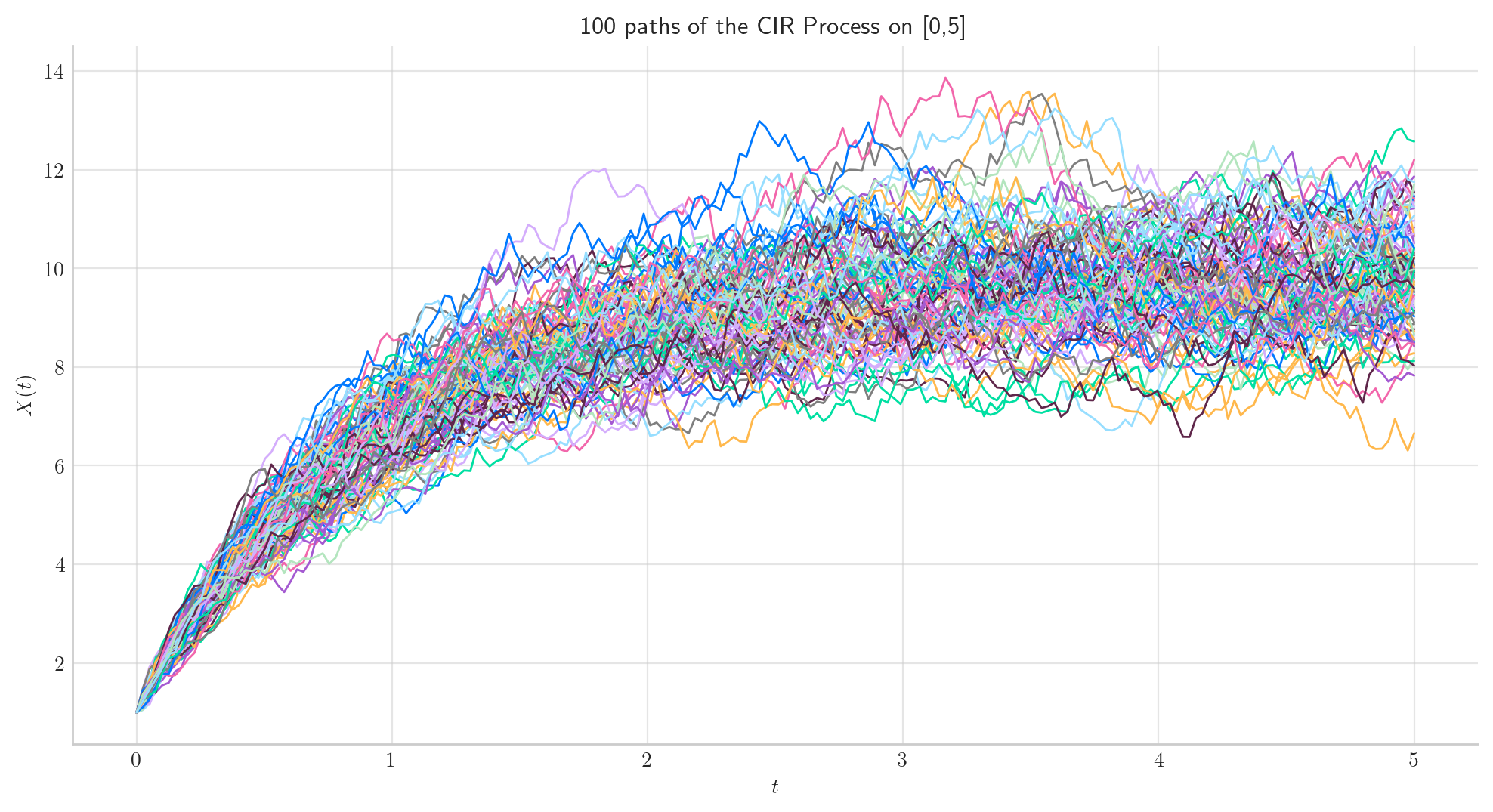
Similarly, we can define the process over the interval \([0, 5]\) and simulate 50 paths with a partition of size 100.
5.5. Long Time Behaviour#
5.5.1. Expectation and Variance#
and
Next, we illustrate the convergence of both the mean and the variance as \(t\) grows. Note that the speed of convergence is determined by the parameter \(\theta\). First, we consider a process with \(\theta = 0.10\).
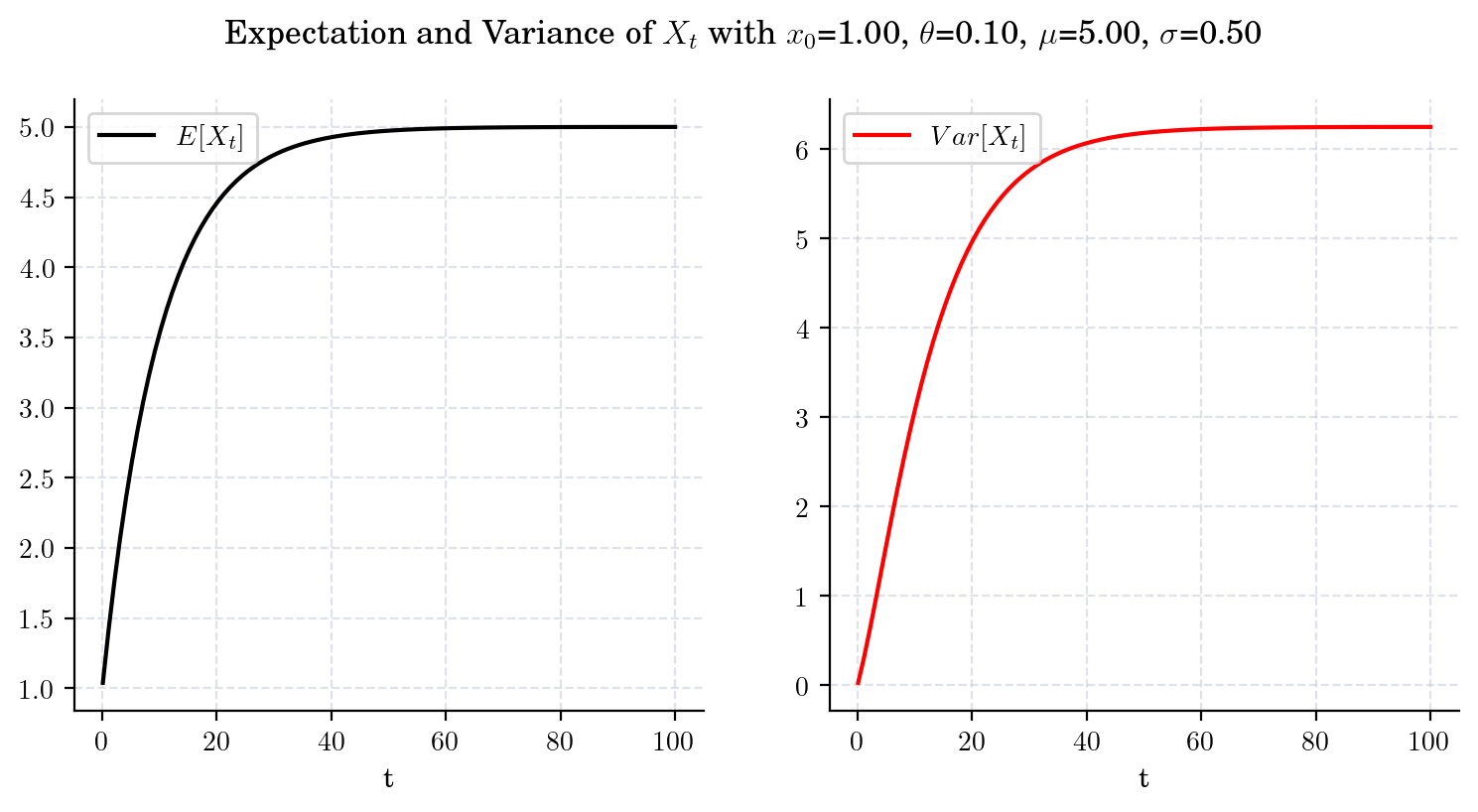
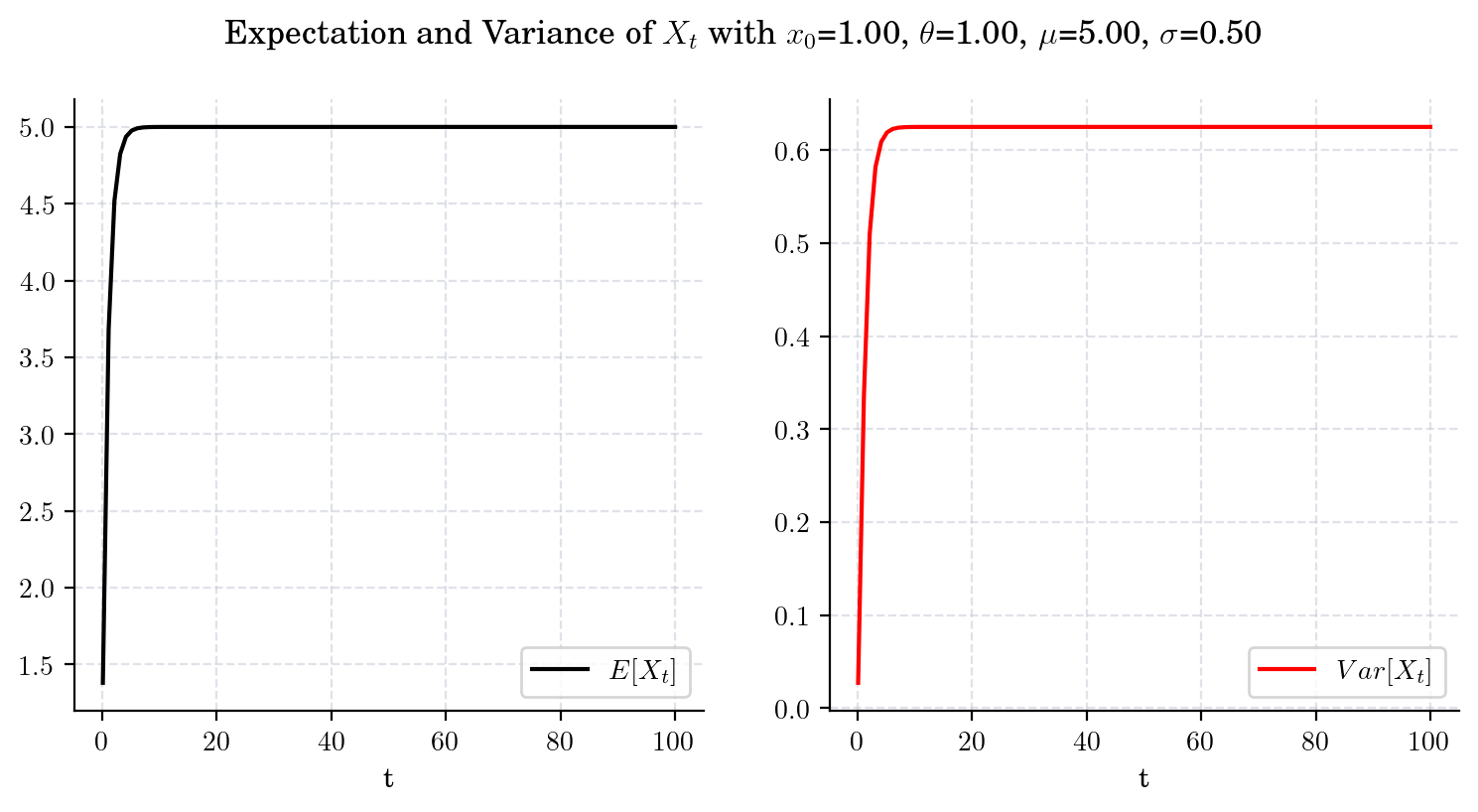
Now, we chage the speed parameter to be \(\theta = 1\) (i.e. 10 times bigger than before) and plot both the expectation and the variance over the same time interval. Clearly, convergence is achieved much faster. Besides, the limit variance is different.
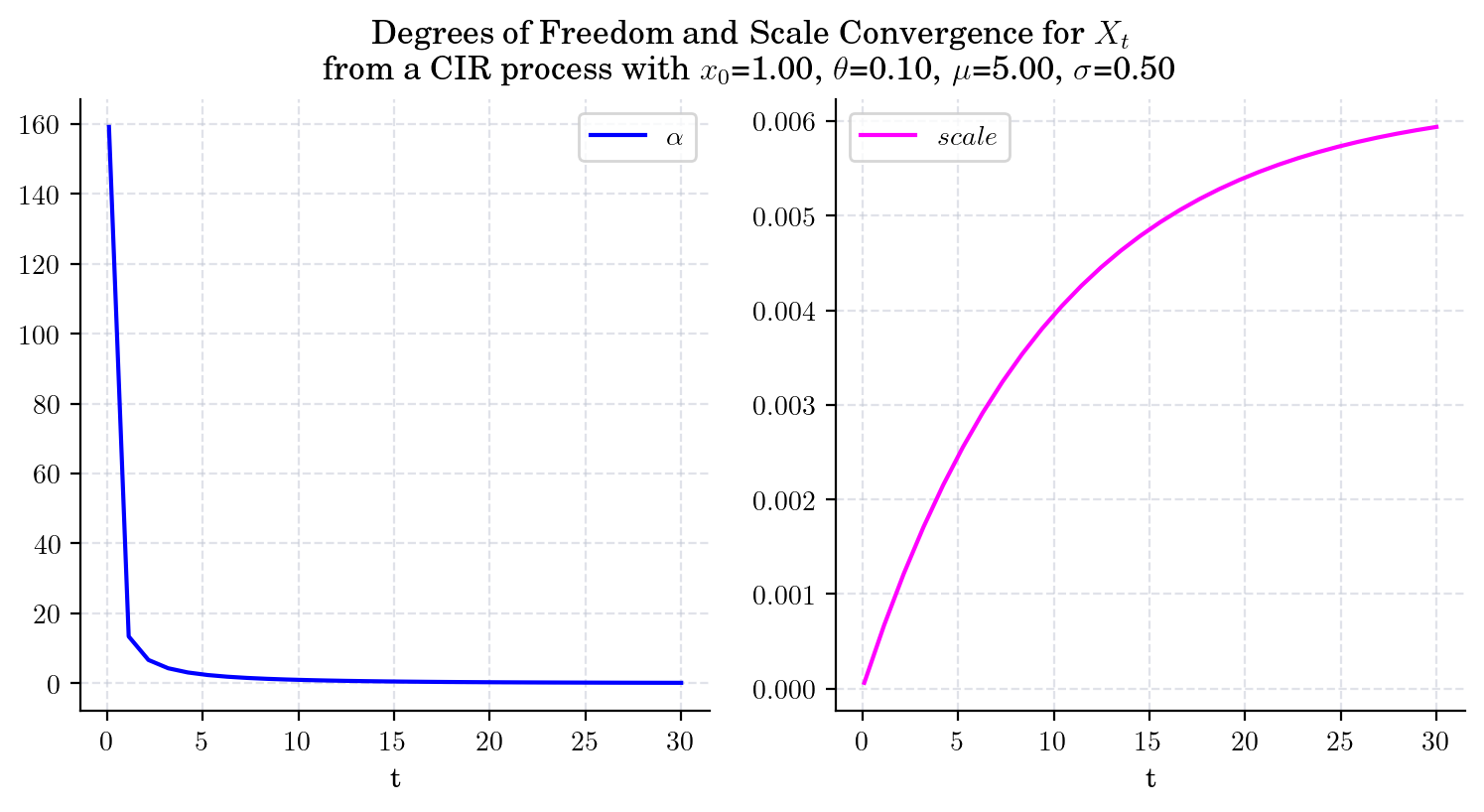
5.5.2. What about \(\delta, \alpha\) and \(scale\)?#
draw_alpha_scale(x0=1.0, theta=0.1, mu=5.0, sigma=0.5, T=30)
5.5.3. Marginal#
Equations (5.7)-(5.10) together with (5.11)-(5.13) imply that distribution \(X_t\) given an initial point \(x_0\), converges to
as \(t\) goes to infinity. Let’s make some simulations to illustrate this convergence.
First, we simulate 1000 paths from CIRProcess(theta=1.0, mu=10.0, sigma=2.0, initial=1.0, T=1.0) over the interval \([0,1]\). Here, we can see the the distribution of \(X_1\) has mean around 6.0. This means that the process has not reached convergence, since we have not arrived to the long term mean \(\mu=10.0\).
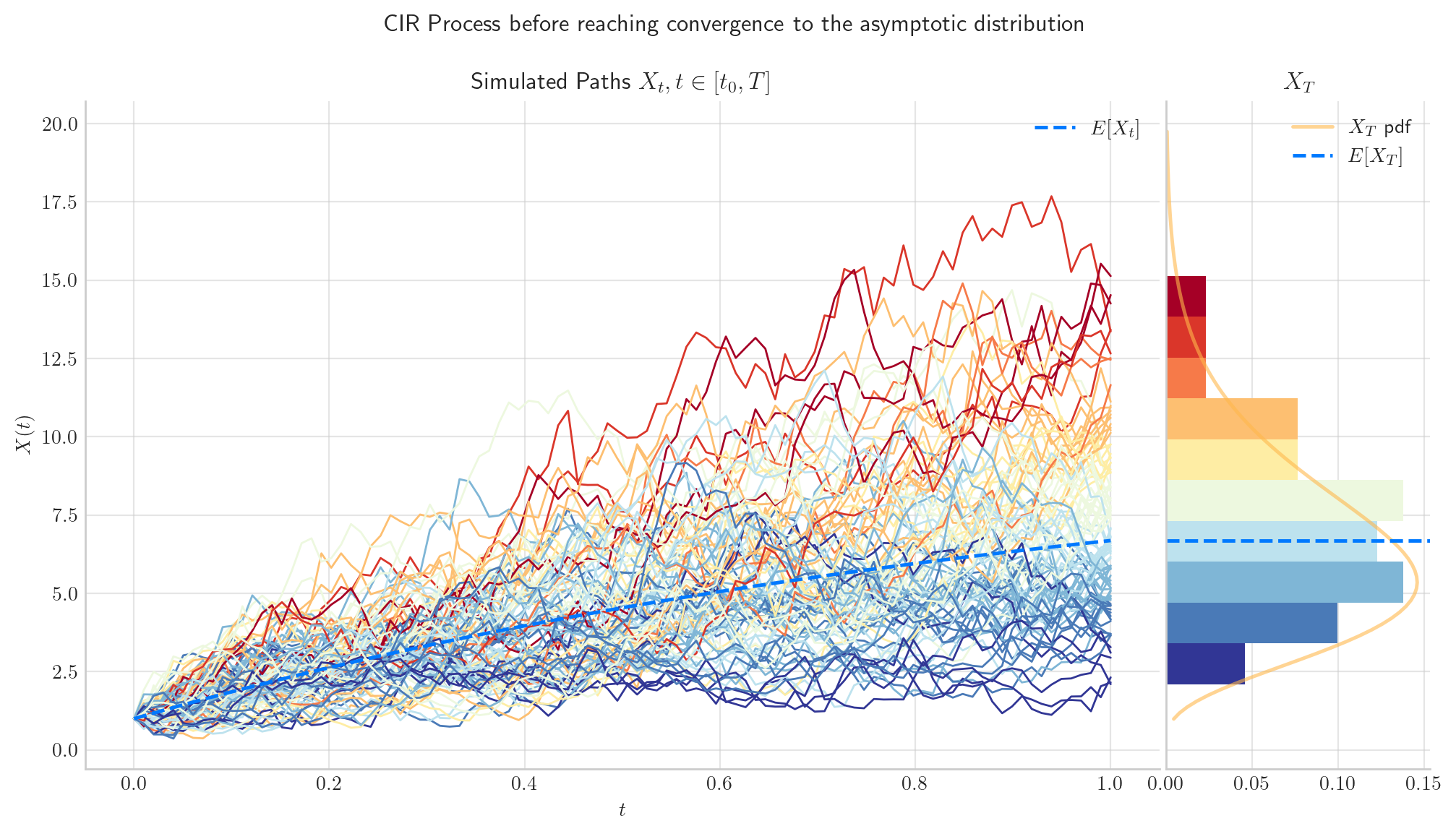
Now, we simulate 1000 paths from the same process CIRProcess(theta=1.0, mu=10.0, sigma=2.0, initial=1.0, T=15) but this time over the interval \([0,15]\). In the picture, we can see the the distribution of \(X_{15}\) has mean equal to the long term mean \(\mu=10\). The expectation has reached convergence!
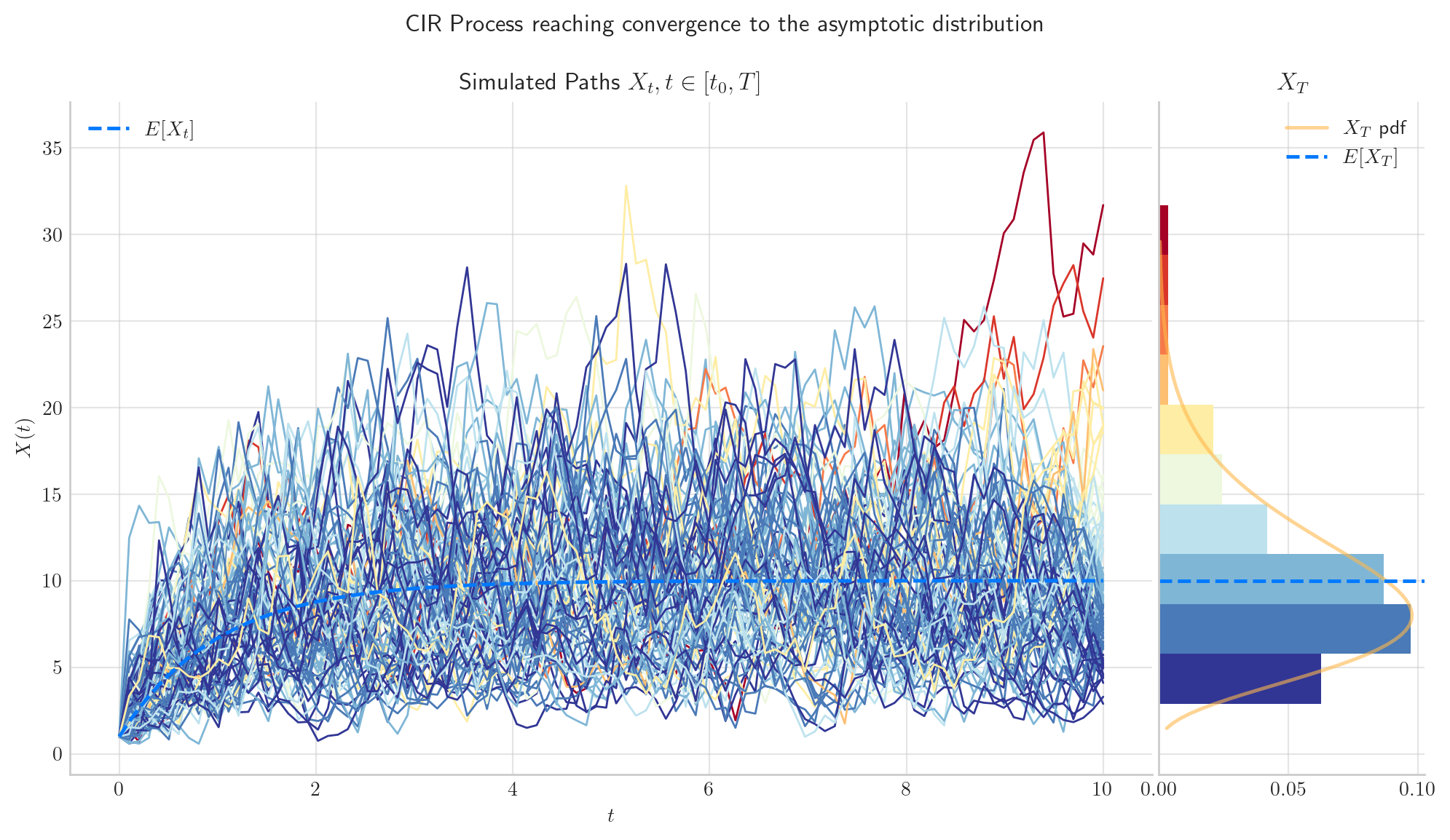
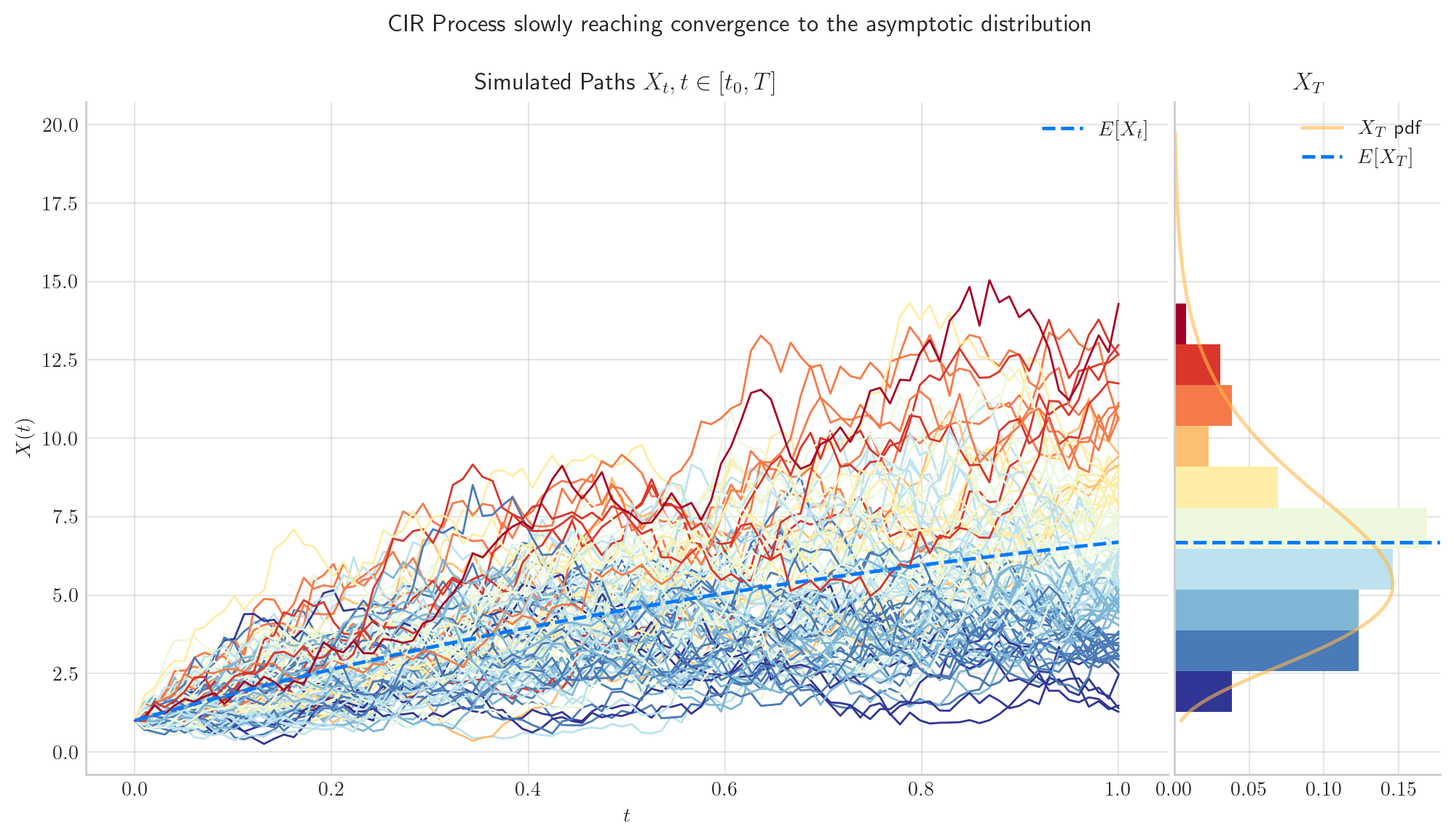
5.5.3.1. The parameter \(\theta\) determines the Speed of Convergence#
# from aleatory.processes import CIRProcess
process = CIRProcess(theta=1.0, mu=10.0, sigma=2.0, initial=1.0, T=1.0)
fig = process.draw(n=100, N=100, title='CIR Process slowly reaching convergence to the asymptotic distribution')
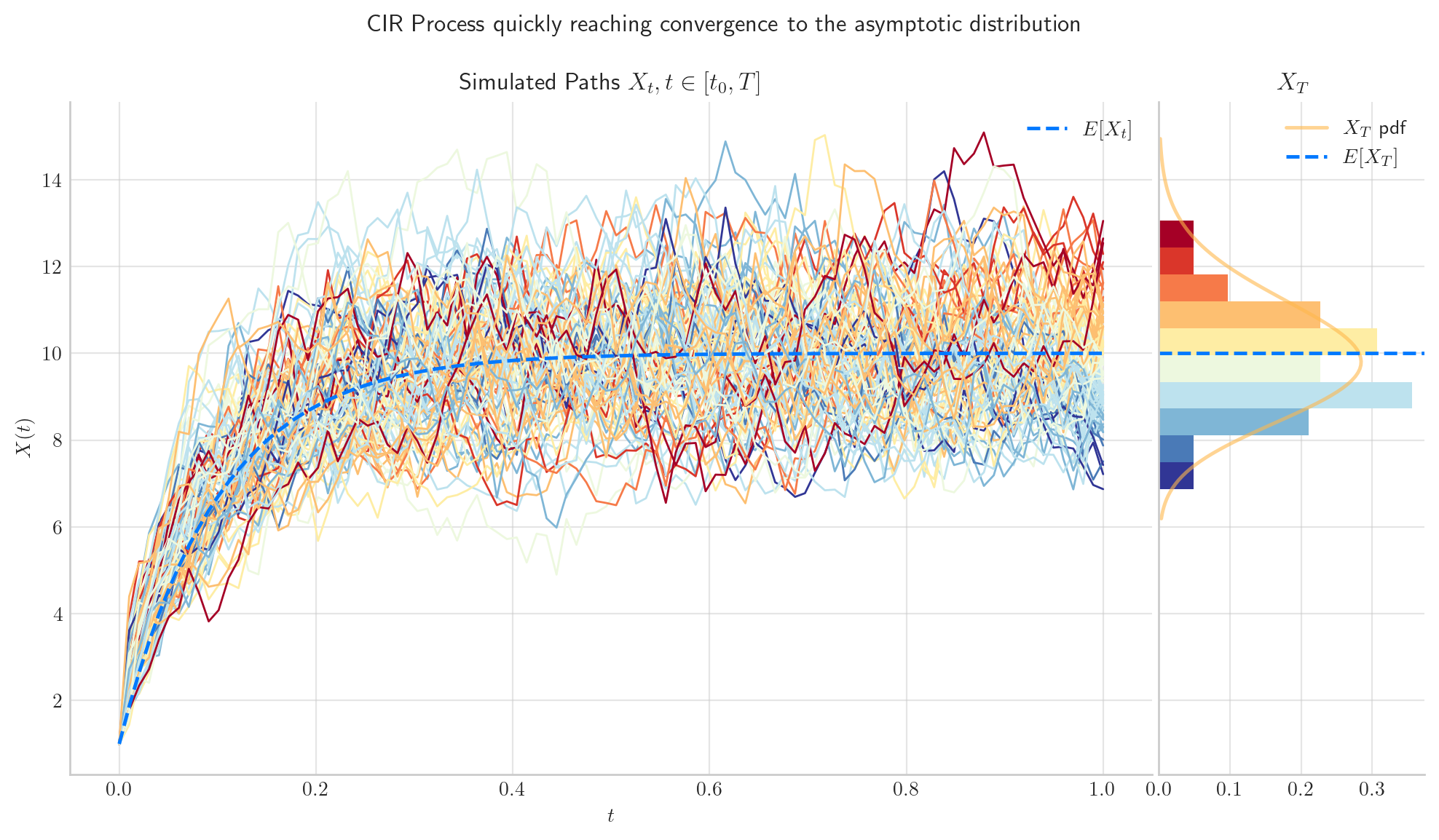
# from aleatory.processes import CIRProcess
process = CIRProcess(theta=10.0, mu=10.0, sigma=2.0, initial=1.0, T=1.0)
fig = process.draw(n=100, N=100, title='CIR Process quickly reaching convergence to the asymptotic distribution')
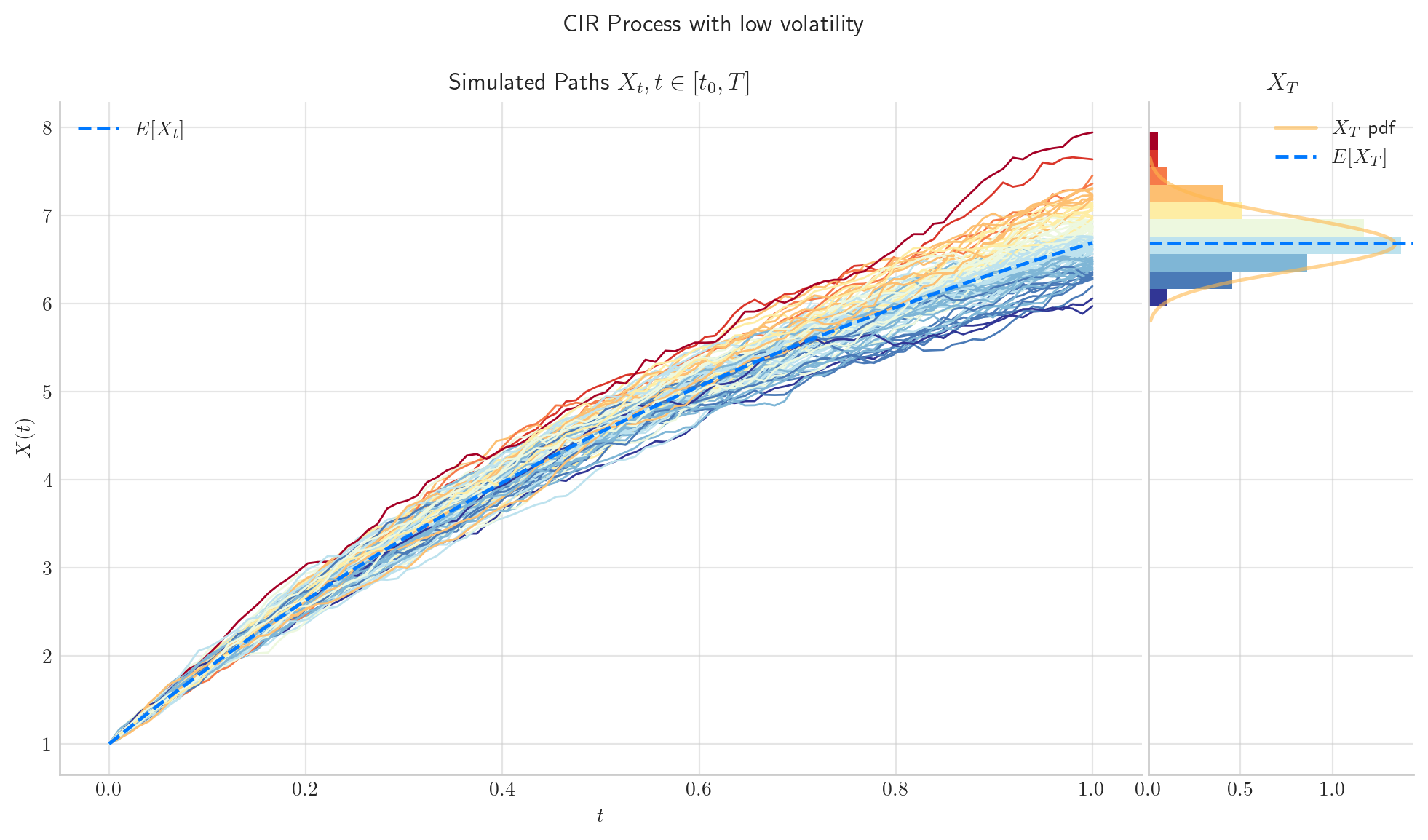
5.5.3.2. The parameter \(\sigma\) determines the volatility in the simulation#
# from aleatory.processes import CIRProcess
process = CIRProcess(theta=1.0, mu=10.0, sigma=0.2, initial=1.0, T=1.0)
fig = process.draw(n=100, N=100, title='CIR Process with low volatility')
# from aleatory.processes import CIRProcess
process = CIRProcess(theta=1.0, mu=10.0, sigma=2.0, initial=1.0, T=1.0)
fig =process.draw(n=100, N=100, title='CIR Process with high volatility')
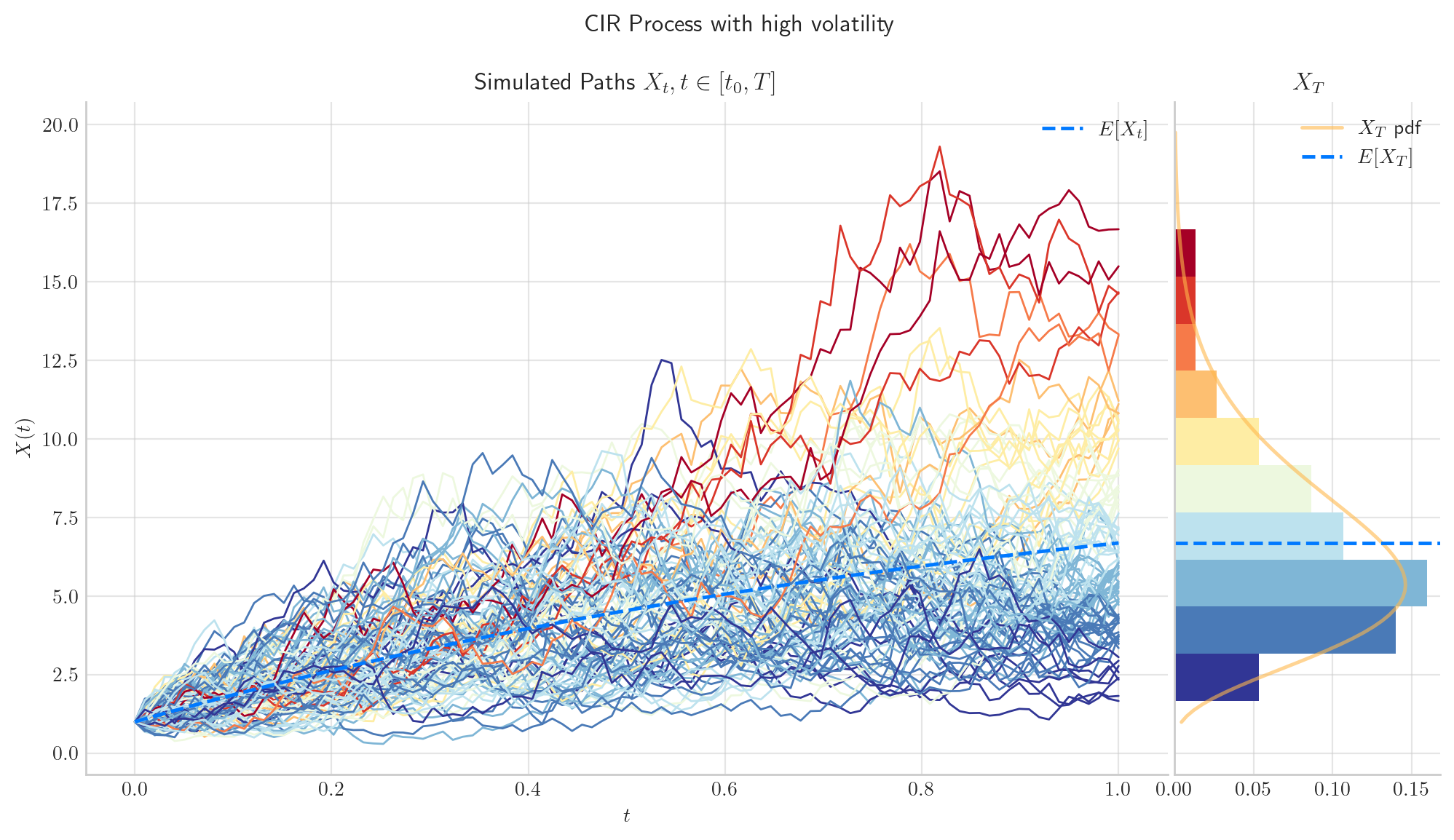
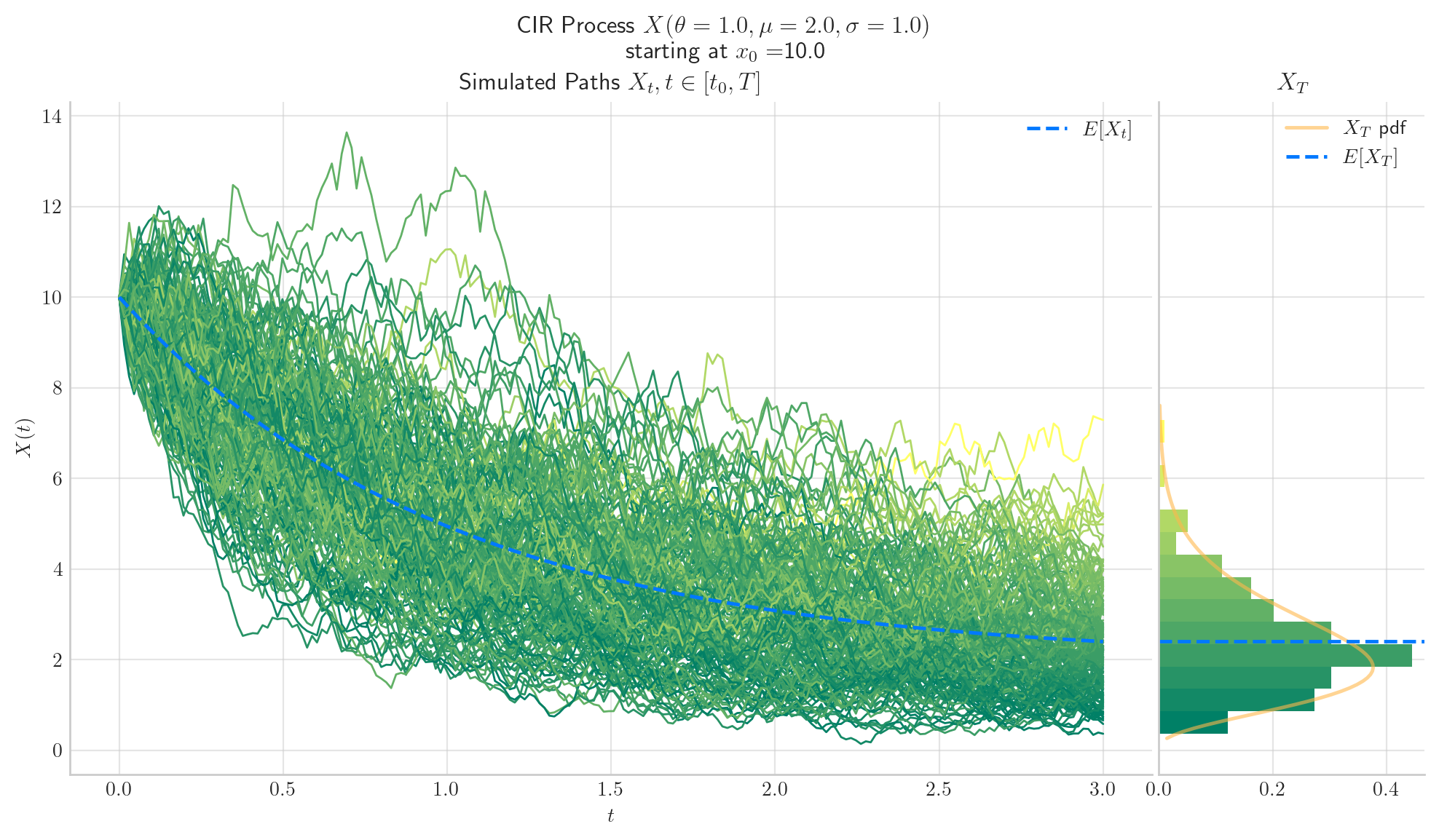
5.6. Final Visualisation#
To finish this note, let’s take a final look at a some simulations from the CIR process.
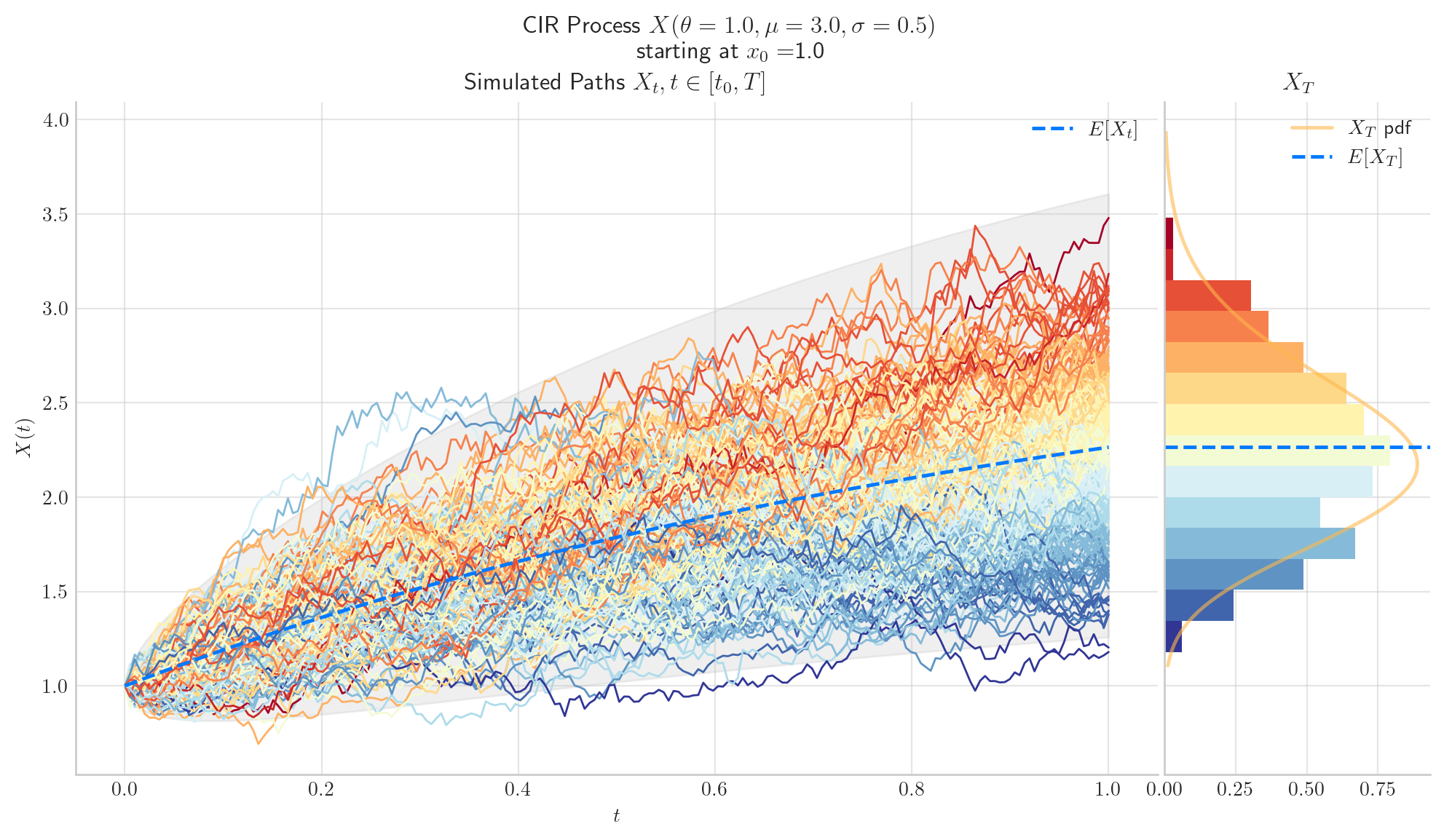
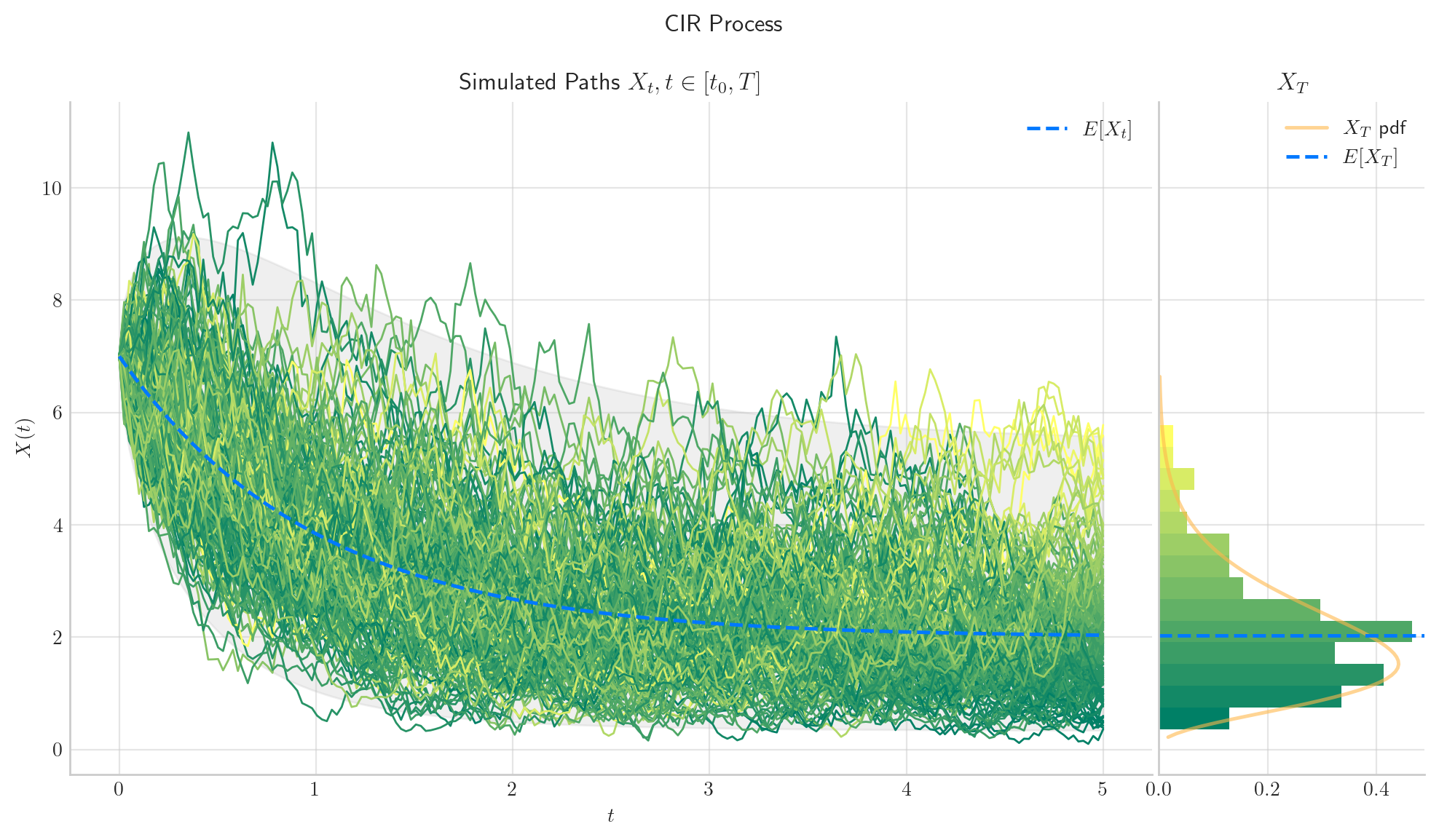
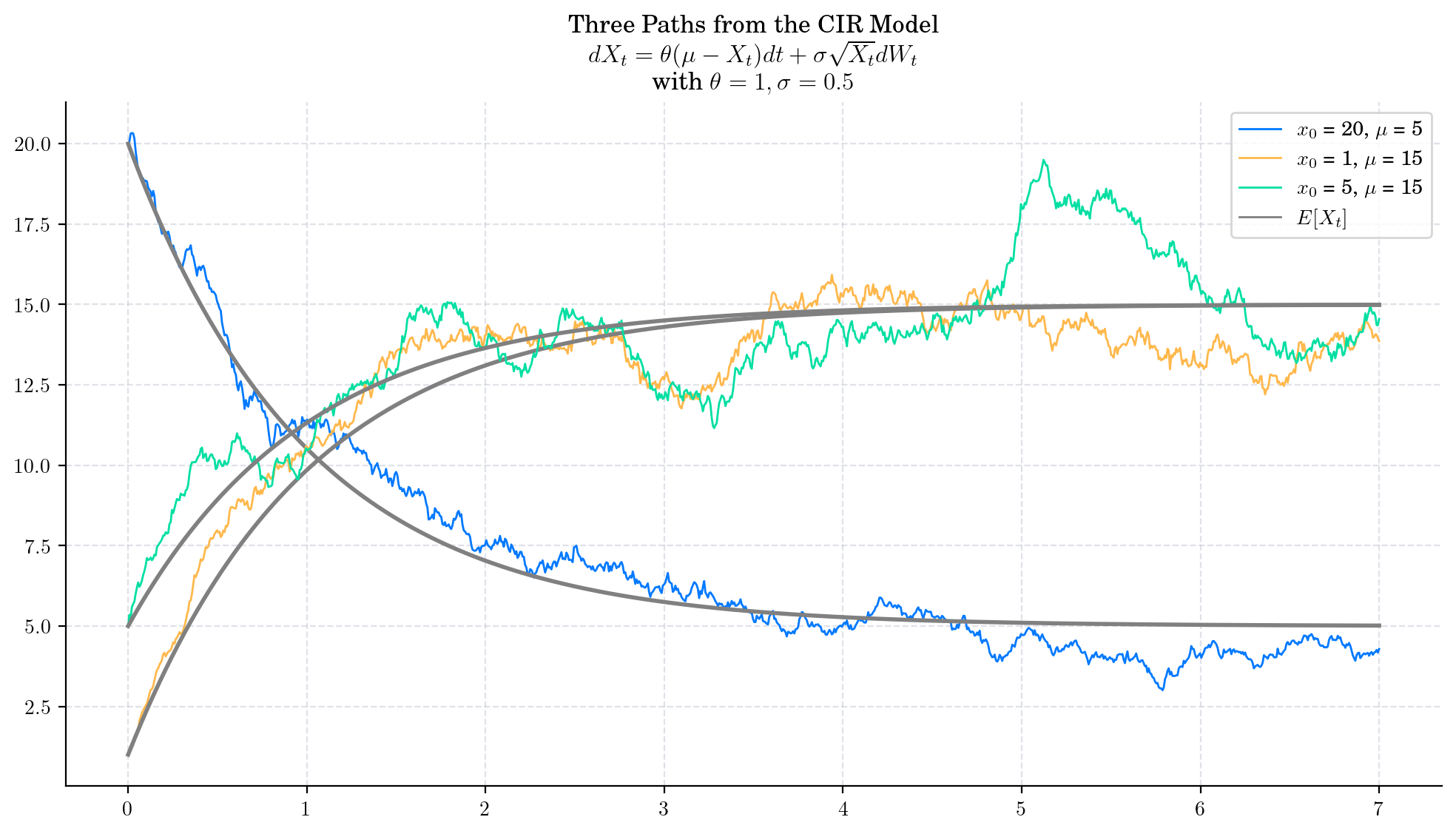
5.7. References and Further Reading#
“Mathematical Methods for Financial Markets” by Monique Jeanblanc, Marc Yor, Marc Chesney; Springer Science & Business Media, 13 Oct 2009